neural network weight prediction
TL;DR: I tried two related tasks: predicting an MLP’s outputs from its weights (easy — works with concat or residual nets), and the inverse problem of inferring weights from input-output pairs (harder — required moving to a Deep Sets architecture, where the bottleneck shifts from sample count to model capacity).
I wanted to build a simple neural network to do a slightly tricky task: can we predict the weights of the model from just the inputs and outputs? Part I walks through a simpler task of confirming that we can simulate a forward pass from a certain architecture, and Part II will delve into the question above.
Part I
We have a well-defined task: given inputs and weights of another, smaller neural net, can we predict its outputs with this network? Since the function defined by the generator net (smaller one) is well-defined and continuous, by Universal approximation theorem (UAT), a sufficiently large ReLU net (nonlinearities are key) can approximate it. The theorem guarantees that this is possible, but provides no details for how to do it. So let’s do it.
Architecture
To keep things concise, we’ll define two layers with a ReLU activation for our data generator. We can easily pass in weight tensors and evaluate any input.
def get_mlp_out(x, w1, w2):
y1 = F.relu(x @ w1)
return y1 @ w2
The predictor net has two network variations we’ll compare.
class XLinear(nn.Module):
def forward(self, x):
h = x
for layer in layers:
h = activation(layer(h))
h = concat(h, x) # reattach original input each time
return output_layer(h)
XLinear has strength over a plain Linear network because the generator input and weights that we concatenate at each layer can skip information bottlenecks from previous hidden layers.
To provide even more scaffolding, we’ll also look at ResLinear (it doesn’t actually have any conv layers like a typical ResNet, but maybe the skip connections would still help).
class ResBlock(nn.Module):
def forward(self, x):
return activation(main_path(x) + skip_path(x))
class ResLinear(nn.Module):
def forward(self, x):
x = input_layer(x)
x = res_block(x)
x = res_block(x)
return output_layer(x)
The x samples are the concatenation of the generator net’s input and weight tensors and the y samples are the evaluated output (using get_mlp_out).
Results
After training with a batch size of 1024 and 50000 training steps, we get the following (note: all the loss curves below use exponential moving average to smooth out the noise).
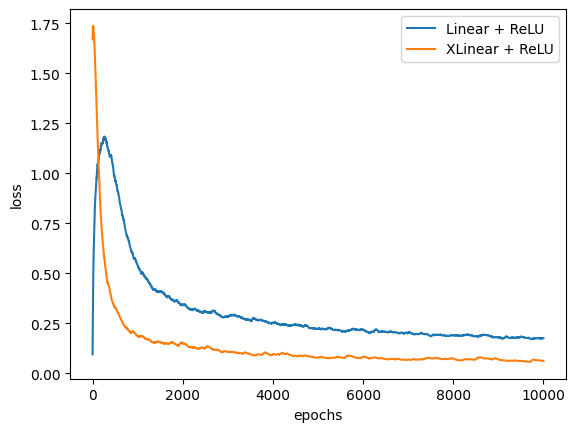
The concatenation technique did work! But ResLinear did even better.
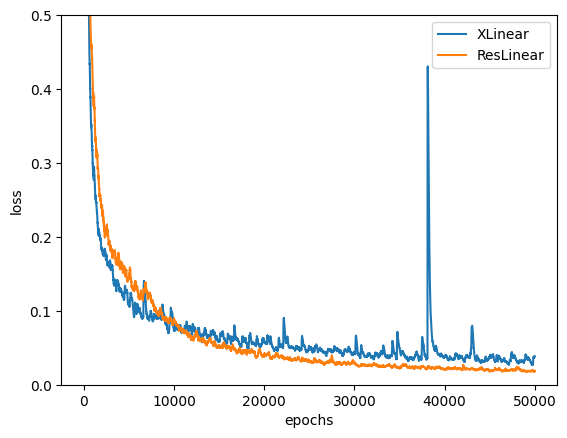
By the end of the training run, we reach a loss of 0.017! This loss can’t be memorization since we sample fresh generator inputs and weights at each batch.
Part II
To reiterate: can we build a weight predictor by taking in the inputs and outputs of a generator network?
My first instinct is to try doing the same thing as above and see what results we get. Before that, a few comments – the possible number of weight matrix combinations is massive. how do we incentivize the bigger network to learn the structure of the smaller one. With sufficient I/O samples, would the smaller model’s architecture be the least lossy path?
To begin, let’s first try a much simpler generator net with only one linear layer.
def get_simple_data(num_unknowns, num_pairs):
# weights are the unknowns
w = torch.randn(batch_size, num_unknowns, 1)
pairs = []
# we take multiple pairs for each input
# to give more info about the weight layer
for i in range(num_pairs):
x = torch.randn(batch_size, num_unknowns)
y = torch.bmm(x.unsqueeze(1), w).squeeze(1)
pairs.append(x)
pairs.append(y)
# ...
Using this data generator, we should expect that our model (we used ResLinear) should perform better when given more equations (num_pairs) than unknowns (num_unknowns) since the system is overdetermined. So we try this out:
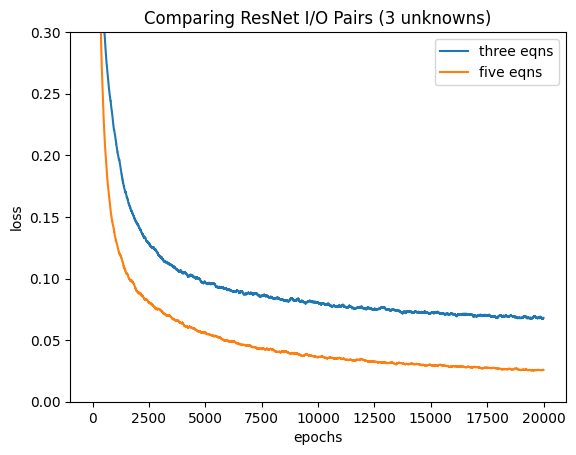
And it worked! The model with five I/O pairs for each weight tensor performed much better. As the network is purely linear, the unknowns can be solved purely by least-squares, so this test is more of a sanity check.
Now, we move onto a more complex generation network that isn’t purely linear.
def get_data_v2(num_pairs):
"""
30 pairs for 15 unknowns (2*5+5*1).
"""
w1 = torch.randn(batch_size, 2, 5)
w2 = torch.randn(batch_size, 5, 1)
pairs = []
for i in range(num_pairs):
x = torch.randn(batch_size, 2)
y = batch_mlp(x, w1, w2) # MLP generator defined above
pairs.append(x)
pairs.append(y)
inp = torch.cat(tuple(pairs), 1)
# ...
Training loop:
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss = nn.MSELoss()
for i in t:
x, weights = get_data_v2(num_pairs=30)
optimizer.zero_grad()
x_eval = torch.randn(batch_size, 2)
# eval true weights on x_eval
w1, w2 = weights
y = batch_mlp(x_eval, w1, w2)
# get weight predictions from test x
weight_pred = model(x)
# eval predicted weights on x_eval
y_pred = compute_weights(x_eval, weight_pred)
output = loss(y_pred, y)
output.backward()
optimizer.step()
We naively apply the same model to this task. However, there are key modifications to the training procedure:
- The loss isn’t computed between the predicted and actual weights. Doing such would make the training incredibly inefficient since there are many valid weight tensors that can implement the same function and we don’t need the exact sequence of them. Essentially, we’re optimizing for functional equivalence.
- The loss is computed between the true y – which is outputted from our generator net – and predicted y – which is the result of running a newly-sampled eval x sample through the predicted weights. This is a Monte Carlo estimate of the expected error over the entire input distribution.
Turns out, despite having 2x the equations as unknowns, loss doesn’t decrease at all. A few reasons why:
- Since we blindly smush the xy pairs into a 1D list in
get_data_v2, we don’t give the model any inductive biases about the groupings of values. This makes learning the I/O mappings an uphill battle. - The input tensors aren’t permutation invariant, meaning the same layout of pairs in a different arrangement is a new unseen example for the model (which it shouldn’t be).
- With the nonlinearity in the generator net now (ReLU!), it’s a lot harder for another model to learn (especially with issues 1 and 2 included).
Let’s try something else: what if we directly embed x and y into some unified vector and have the model predict weights from here?
Architecture
class PairEncoder(nn.Module):
def __init__(self, x_dim, y_dim, embed_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(x_dim + y_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, embed_dim)
)
def forward(self, x, y):
pair = torch.cat([x, y], dim=-1)
return self.net(pair)
Now, we have a pair encoder that transforms a concatenated x and y into an embedding vector.
class WeightPredictor(nn.Module):
def __init__(self, x_dim, y_dim, out_dim, embed_dim):
super().__init__()
self.encoder = PairEncoder(x_dim, y_dim, embed_dim)
self.decoder = nn.Sequential(
nn.Linear(embed_dim, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, out_dim)
)
def forward(self, x, y):
embeddings = self.encoder(x, y)
# avgs across input pairs in each batch.
# key for permutation invariance.
embed_pooled = embeddings.mean(dim=1)
return self.decoder(embed_pooled)
Finally, we decode these embeddings into the weights.
For all the training runs below, we use a learning rate of 1e-3 and Lecun weight initialization for the data generator (I didn’t do either in the first iteration and that was a huge mistake). Our embedding dimension has size 128.
Results
Following the same paradigm of predicting weights from the train input and using a new eval x to make a y prediction, we get this graph where we try predicting 15 unknowns from the weight layer using 20, 30, and 45 equations.
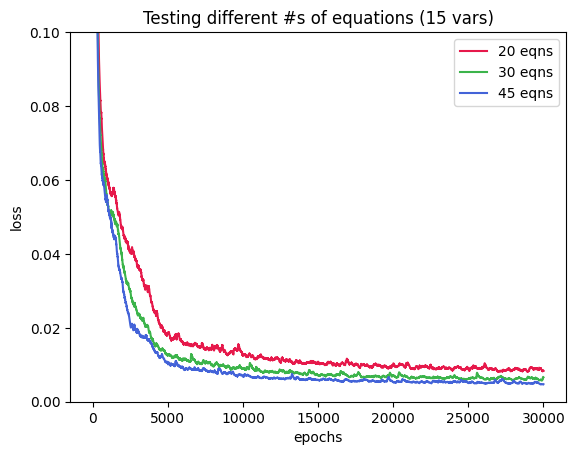
Cool results – our new method works! The loss goes down to 0.005 for the 45 equation curve and only a bit more for the other two plots. Let’s scale up the weights of the generator model and see if we get the same trend.
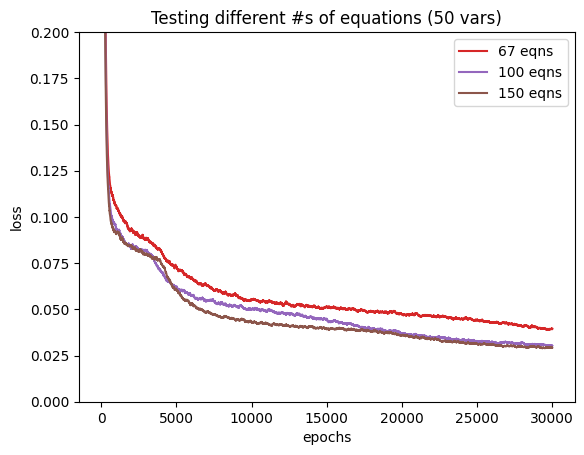
I followed the same scaling factors as before: x1.33, x2, and x3, but with 50 unknowns instead. To compare, let’s use $R^2$, the fraction of variance explained by the model.
$$ \begin{array}{c|cc} \text{Equations / Unknowns} & \text{15 unknowns} & \text{50 unknowns} \\ \hline 1.33\times & 98.3\% & 91.7\% \\ 2\times & 98.6\% & 93.6\% \\ 3\times & 99.0\% & 93.8\% \end{array} $$We see that with more unknowns, the problem is genuinely harder per-unit-of-variance, with 5-6% less explained variance at each ratio. Also, there’s saturation from 2x to 3x the equations for the 50 unknowns problem but we still see improvements with the 15 unknowns counterpart. One possible hypothesis for this behavior is the embedding layer bottleneck: the PairEncoder tries collapsing all pairs into a 128-dim vector. With more unknowns, the same fixed vector needs to hold more information. Furthermore, mean pooling throws away the spread and correlations between pairs which do actually matter – switching to attention pooling could make a huge difference.
Discussion
Previously, we raised a question on whether the generator net’s weight layout provides the least-cost option for predicting the right outputs. It’s not clear if the training process results in a weight configuration that falls in the same equivalence class as the true set of weights or the predicted weights happen approximate the function only for this training distribution and not elsewhere. Further tests might include adding more nonlinearities to the generator network or sampling the evaluation x tensors from a different distribution and see if accuracy still holds up.
Turns out, the architecture we used is essentially a Deep Sets model where we encode the inputs independently, pool across the set, and decode. It’s advantages permutation invariance and the ability to handle input sets of varying sizes. It’s cool that our pretty simple weight prediction challenge independently arrived at the same methods as the paper.
There are many avenues to continue this experiment, from increasing the embedding size to see if it’s the bottleneck to scaling the generator and predictor networks. Checkout the code and email me what you think. Thanks!